Hello Everyone !
Today, I want to write about Large Language Models because they are getting interest day by day and so I want to give you a brief overview behind the logic of LLM’s : Attention Mechanism.
May be you know about the math behind LLM’s or not, no problem. I will not get you bored 🙂 So let’s start.
Sequential modelling, transduction models, machine translation tasks are being focused by AI Scientists for more than three decades. With the invent of Recurrent Neural Networks, Long Short-Term Memory, and Convolutional Nets, the research about predicting sequential tasks and their usage area in several areas like time-series forecasting, NLP tasks increased.
RNN’s got state of art results in sequential tasks but there is always a room for improvement. There were problems like remembering long-sequential dependencies, complexity and also computational cost of algorithms was another concern.
Researchers continue to find a way that algorithm could handle all the data and highlight the main parts of it and Google come up with a new idea to the world : Attention Mechanism.
What makes it valuable ? Well, Attention mechanism is capable of focusing the all parts of the data either its long dependencies or bringing valuable parts by compute effective matrix multiplications. Simply one can say that attention mechanism is mapping a query and a set of key-value pairs to an output where query, key and values are all vectors.
Let’s talk a bit the math behind it:
If you want to use all information from data then you should focus on all parts of data. But how ? Let’s concern that your data is about a single sentence : ” You love statistics”. How to get information about this data ? Here the aim is to get a vector embedding using transformer architecture called Encoder – Decoder stacks and this can be done using attention function. We can query all single words in our embedding vector and get their corresponding context vector results by using attention function.
I know the example is too small but for illustration purpose I want to highlight querying the word “love”:
So lets dive in : Think that with a encoder layer you translated this data in 1×3 dimensional matrix like:

and you also have a weight matrix to be updated by neural algorithm:

Now all you need is a finding a way to get a result if you query the word “love”, by multiplication of matrices. So here is the formula:
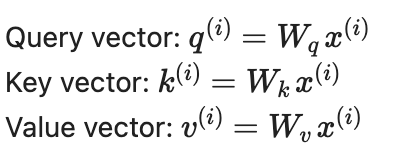
If you multiply related weights with related vectors, you will have a score called “attention”. Lets write it step by step:
1-) Using Wkey, Wquery, Wvalue weigths calculate key, value, query vectors
2-) Since we interested in querying “love” word embedding, get unnormalized attention scores using dot product of query2 and keys
3-) Using softmax function normalize attention scores
4-) multiply normalized attention scores with values and get final context vector.
Let’s show it:
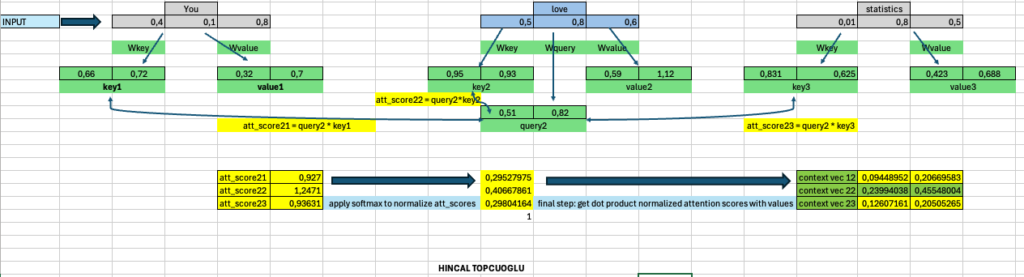
That’s all ! You calculated the context vector for your interest word embedding “love” ! and using this information (with a big data) you can calculate every words’ context vectors which will allow you highlight your data’s most important features. Then you can create your own chatbots, get summarizations, language translations and so forth.
I uploaded the calculation file here, Its my own work, so you can use it to understand the logic.
I will continue from here to understand LLM’s in another posts.
Thank you for reading !
References Papers:
Hochreter, Schmidhuber – Long Short-Term Memory 1997
Vaswani 2017 – Attention is all you need
Hincal Topcuoglu